Engineering Cyber-Physical Swarms
Talk @ Aarhus Universitat
🎤 Gianluca Aguzzi
2022-08-29
About Me
PhD Student @ Università di Bologna – Alma Mater Studiorum
Background on Software Engineering
Main Research Interests


Table of Content
-
Introduction On Cyber-Physical Swarms
-
Aggregate Computing – In a nutshell
-
Main Concept of Multi-Agent (Reinforcement) Learning
-
Preliminary Work & Research Directions
Cyber-Physical Swarm
Swarm Behaviours Cyber-Physical Interaction
Context
Many Networked Agents
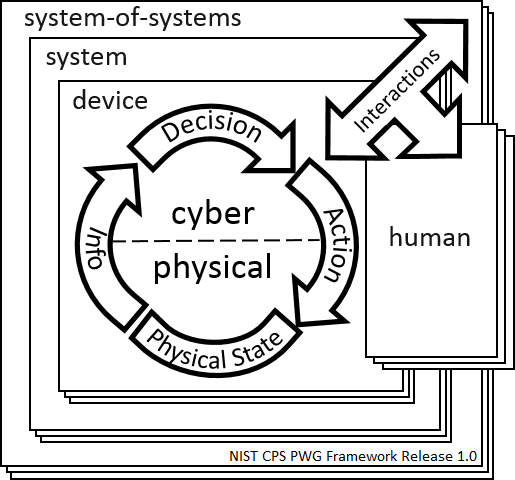
Cyber-Physical Systems
Collective Behaviour
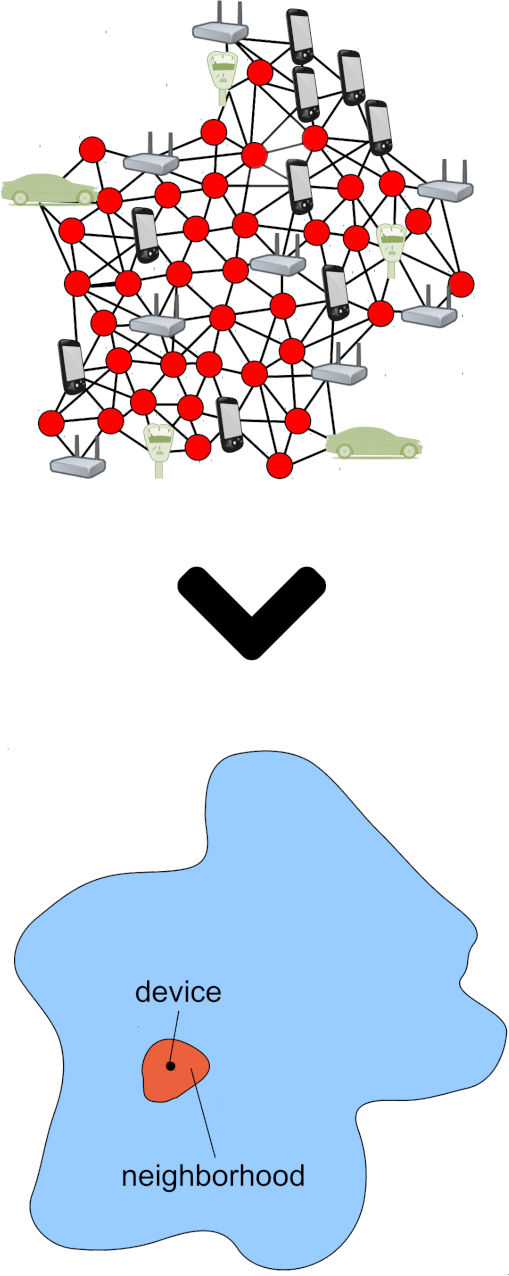
Why we do care about it?
- Pervasive/Ubiquitous Computing
- Systems of today!
- Traditional “Approaches” need significant improvement
Examples
Swarm Robotics

Crowd Engineering

Smart Cities

How??
-
Goals
- Robust Collective Behavior
- Self-* Behaviours
- Decoupling from Functional and Non-Functional aspects
-
Challenges
- Distributed Control
- Failures
- Global-to-local mapping
- Uncertanties
Inspiration Nature
Ants
Bees
Fish School
Engineering “Artificial” Swarms
-
Model
- How can we describe the dynamics of a systems?
- Homogenenous Behaviour
- Neighborhood or Environment based interactions
- Proactive execution model
-
Language Specification
- How can we specify a collective behaviour?
- Predicatable Emergent Behaviours
- Good abstractions
-
Simulation
- How can we verify our collective programs?
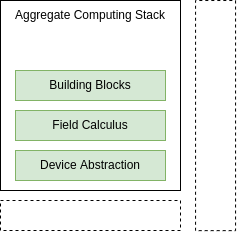
Aggregate Computing
Programming the Aggregate!
Super-Condensed Overview
Aggregate Computing A top-down global to local functional programming approach to express self-organising collective behaviours
Computational Field
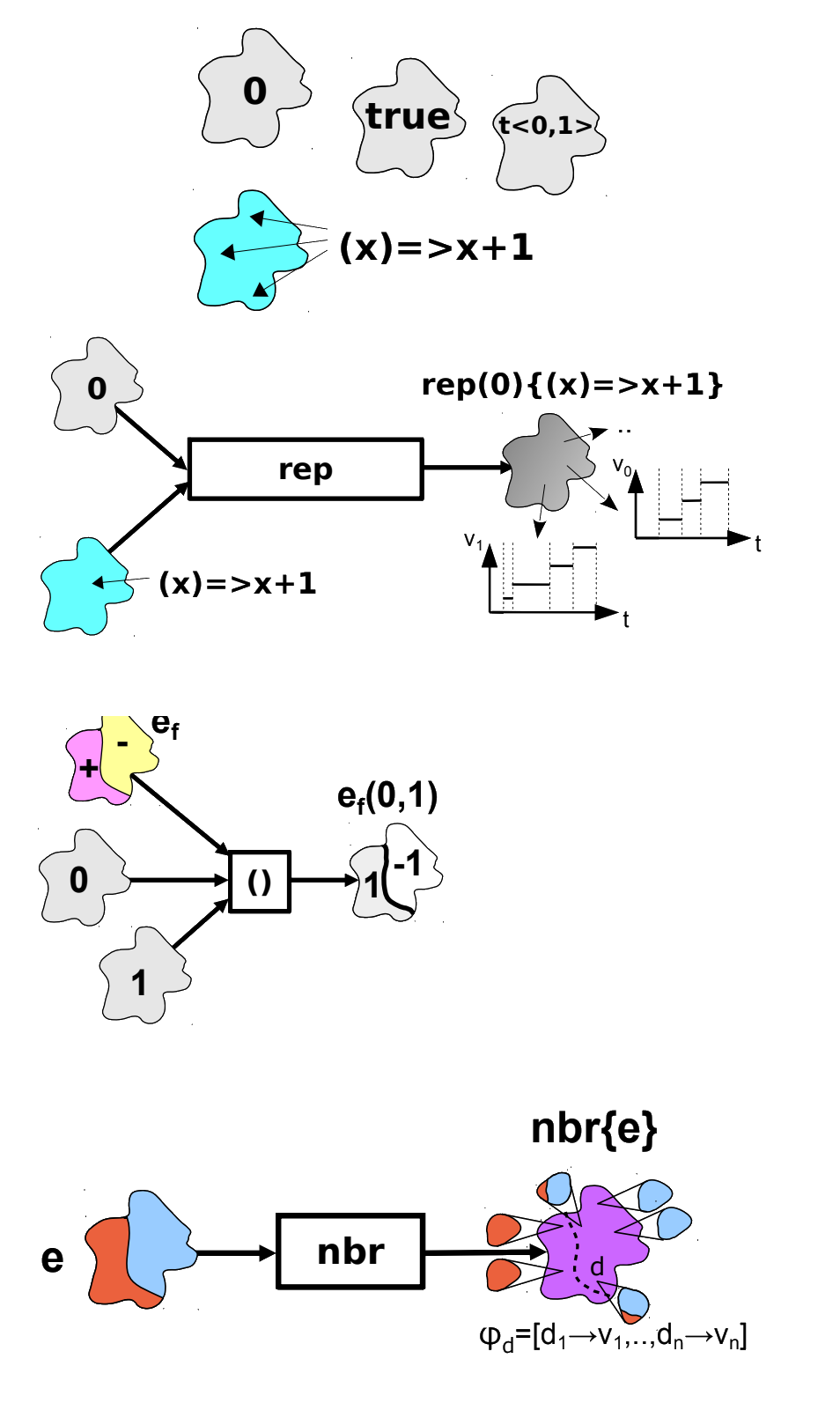
Field Calculus
Composable API
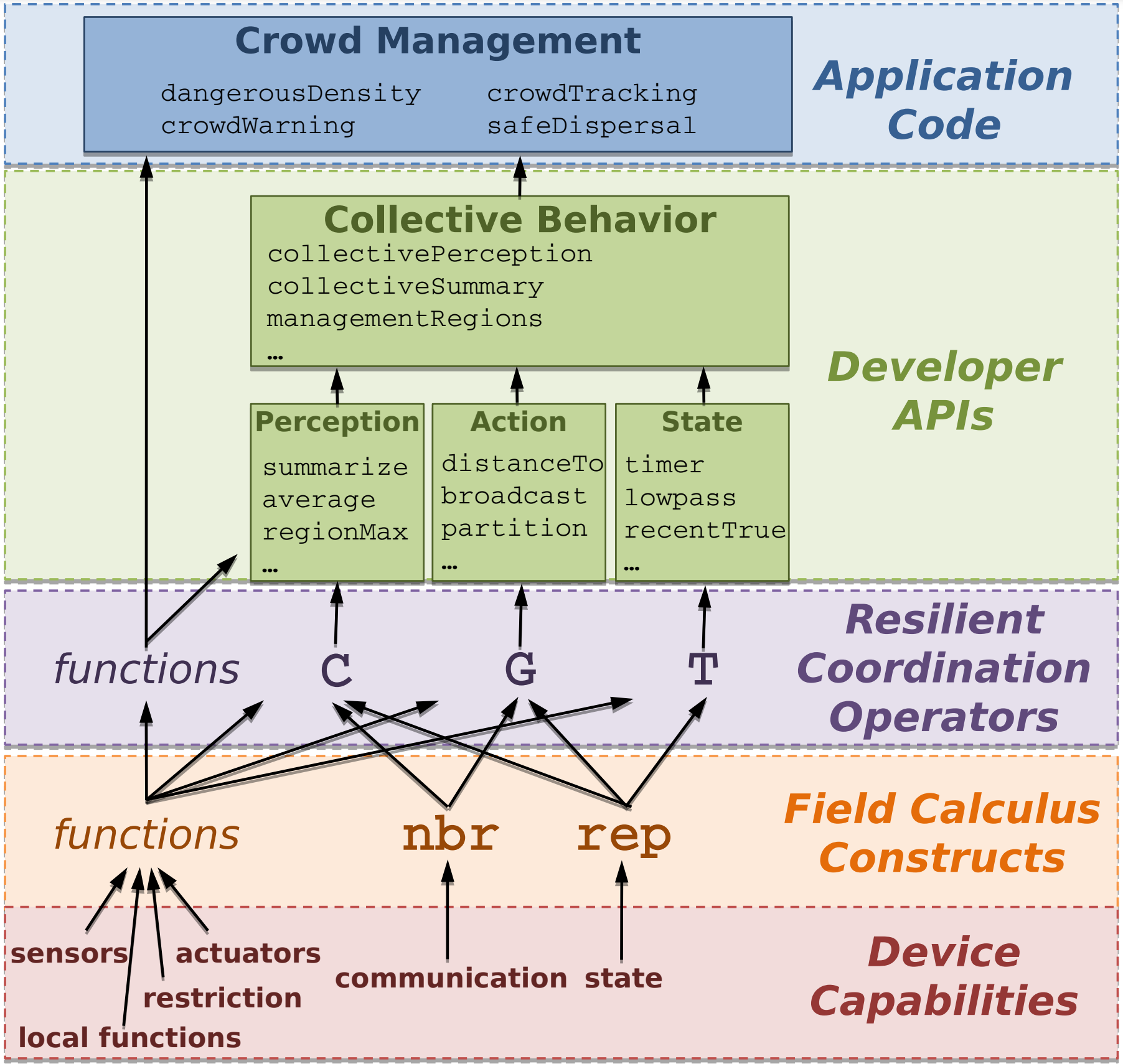
Reference: J. Beal et al, Aggregate Programming for the Internet of Things
Computational fields
Distributed space-time data structure $ \phi: D \rightarrow V $
- E: a triple $\langle\delta, t, p\rangle$ – device $\delta$, firing at time $t$ in position $p$
- Event domains D: a coherent set of events (devices cannot move too fast)
- field values V: any data values
Constant

Input (Sensors)

Actuations

Main Constructs
Field calculus
Conceptually: $ \phi \rightarrow \phi$Field Evolution
def rep[X](init: => X)(evolution: X => X): X
Neighbourhood Interaction
def nbr[X](query: => X): X
def foldhood[X]
(init: => X)
(accumulator: (X, X) => X)
(query: => X): X
Domain Partition
def branch[X]
(condition: Boolean)
(th: => X)
(el: => X): X
Space-time Universal
Global interpretation
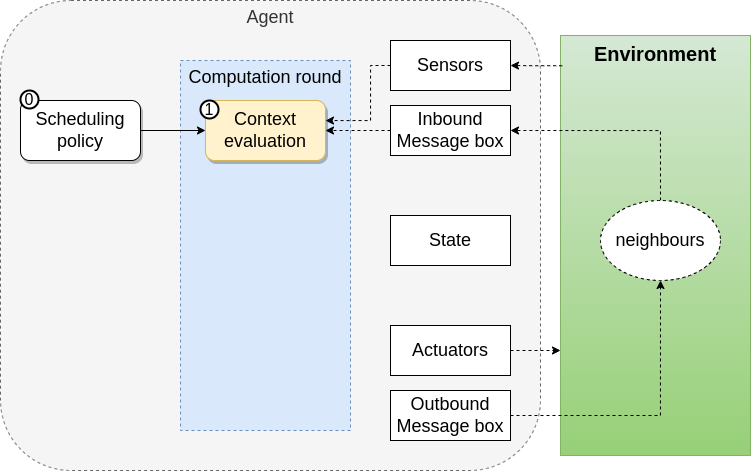
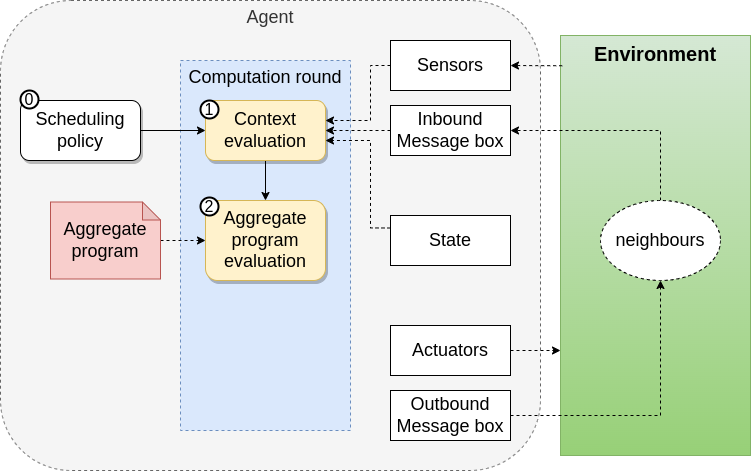
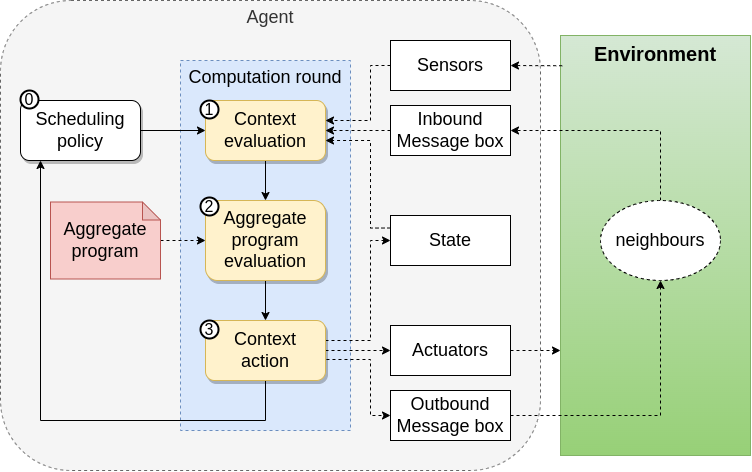
Execution Model
Proactive and Periodioc execution of rounds
-
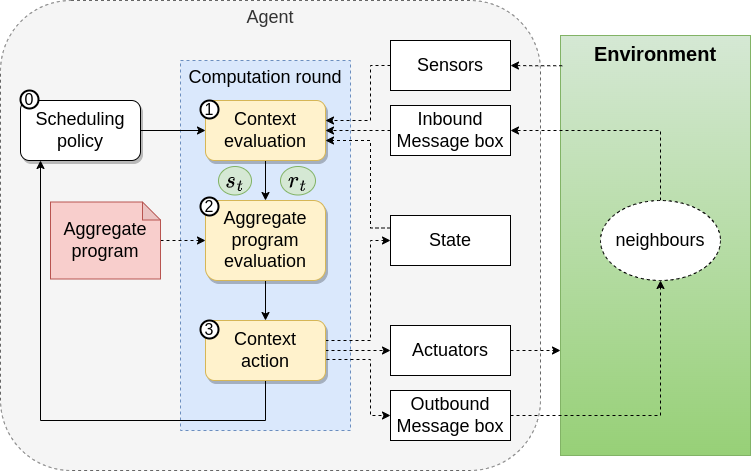
Context Acquisition
- Sensors Data
- Neighbourhood Information
-
Program Evaluation
- Export Generation
-
Context Action
- Export Sharing
- Actuations
What can we do with Aggregate Computing?
Collective pattern
Gradient Cast

Broadcast information from sink nodes
Data collection

Collect data into sink nodes
Sparse Choice
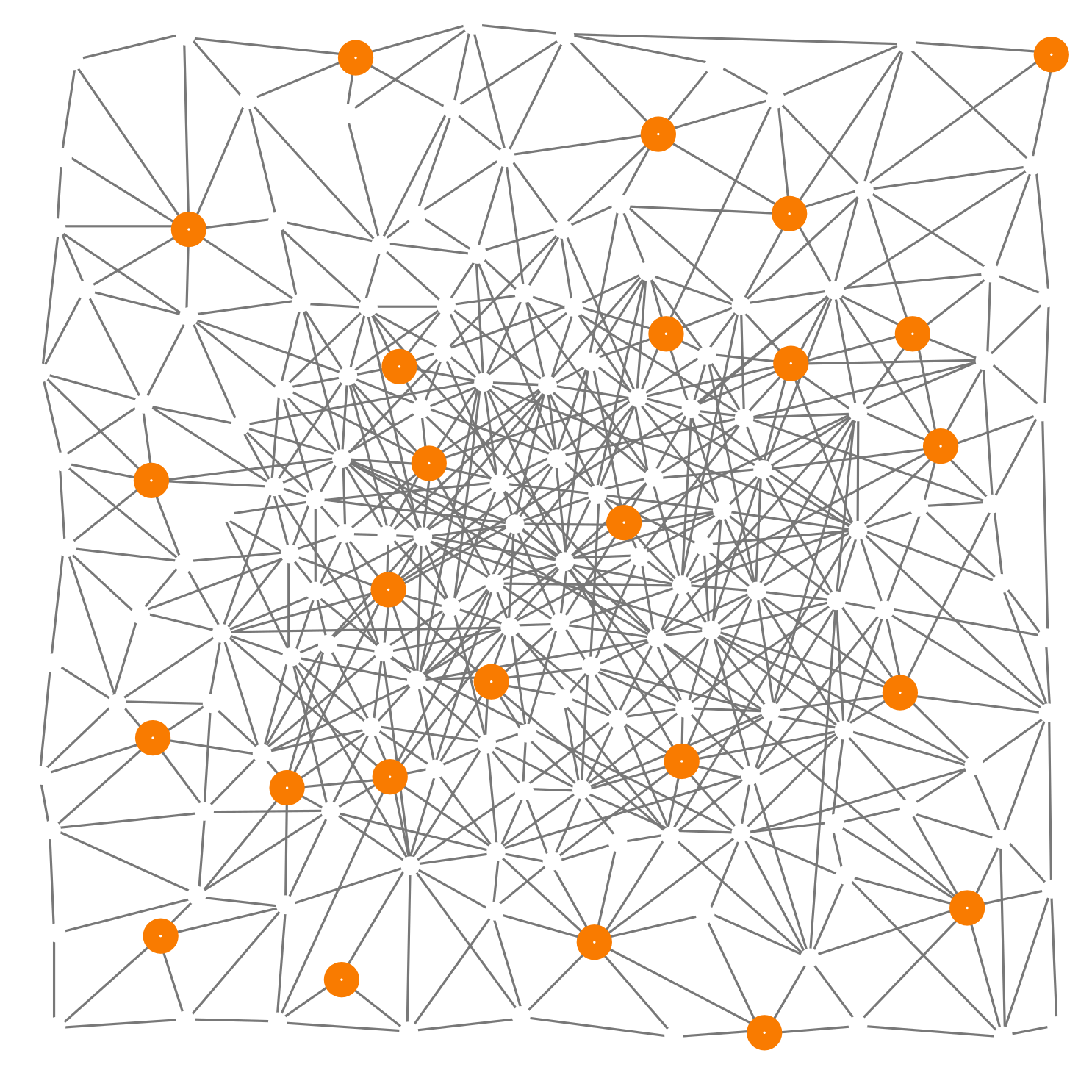
Distributed leader election
Self-organising blocks
What can we do with Aggregate Computing?
Relevant examples
Crowd Engineering
High-Level API
Distributed Resilient Sensing
SCR pattern
Concurrent Activities
Aggregate Processess
Why Aggregate Computing?
- Is practical!
- Programming Languages: ScaFi, Protelis, FCPP
- Simulation Framework: Alchemist
- Fast prototyping: Playground
- Relevant properties have been proven!
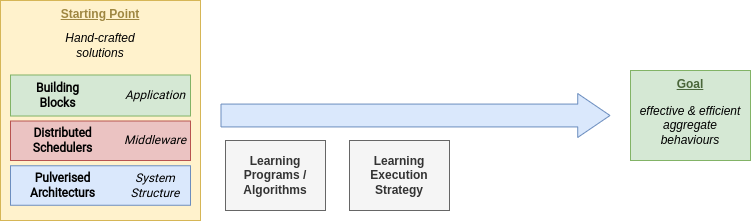
Research Directions
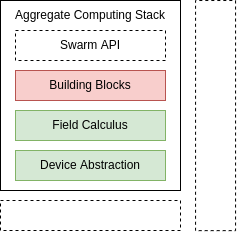
Reality Gap
- Current status: good abstractions & building blocks
- Prototypical Idea for High-Level API for Swarms Behaviours
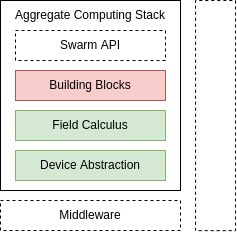
- Engineering a flexible middleware is hard
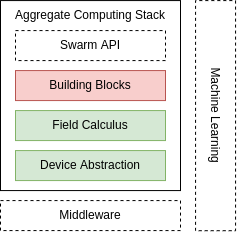
- Machine Learning could improve the entire stack!
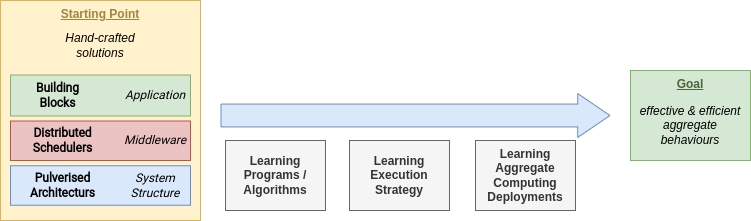
Research Directions
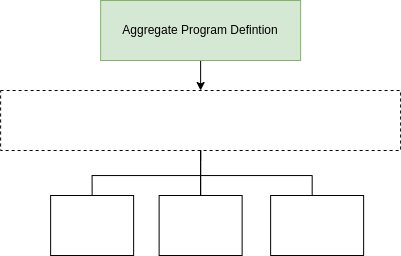
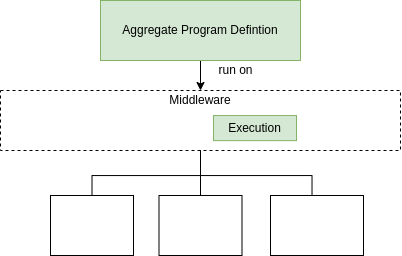
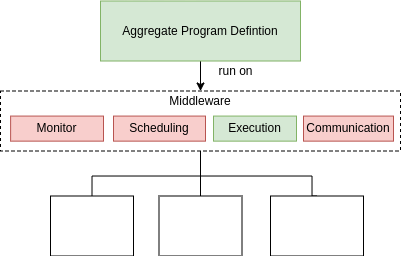
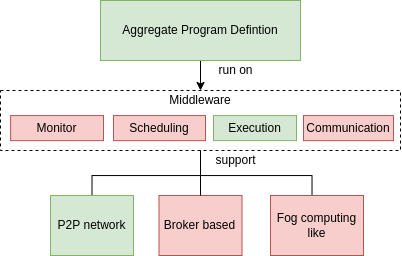
Middleware Status
- Well-known execution strategy for Aggregate programs
- Lack of Monitoring, Scheduling, Communication modules
- Limited IT network supported
Research Directions
Machine Learning Roadmap


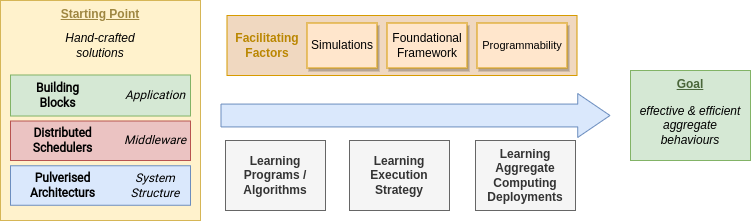
Why?
- Improve adaptability
- Improve efficiency & efficacy
- Mixed-approach, let machine learn the unknown
Broad Impact
- Engineering Collective Intelligence
- Green Computing
- Multi-Agent Reinforcement Learning
- Hybrid Programming Paradigm
Multi-Agent Reinforcement Learning
Overview
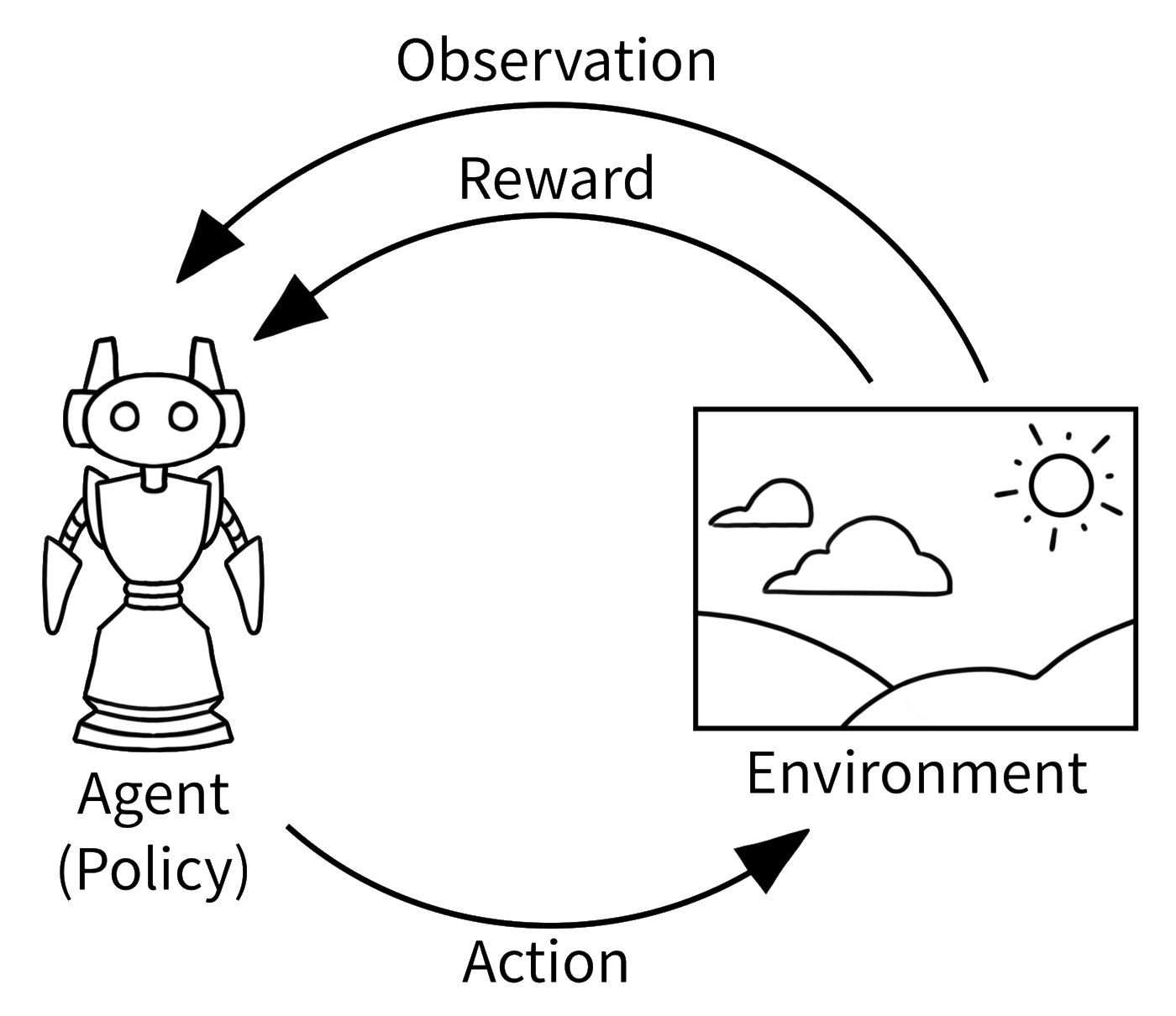
Reinforcement Learning
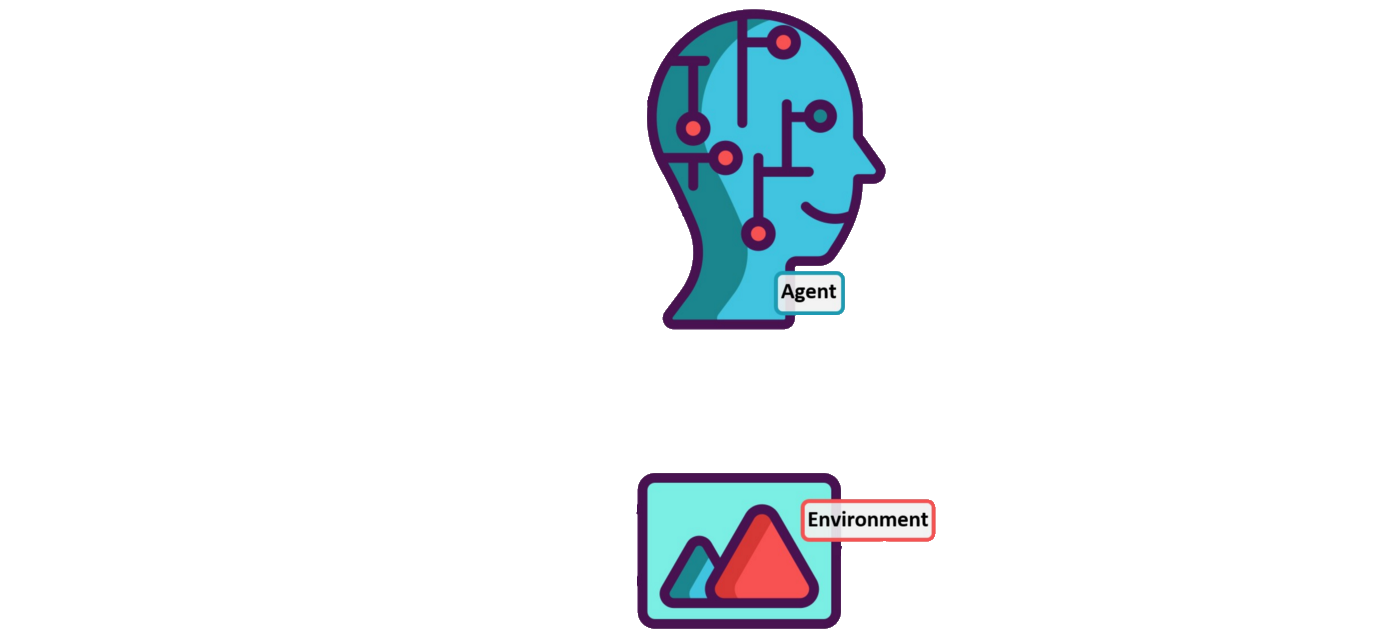
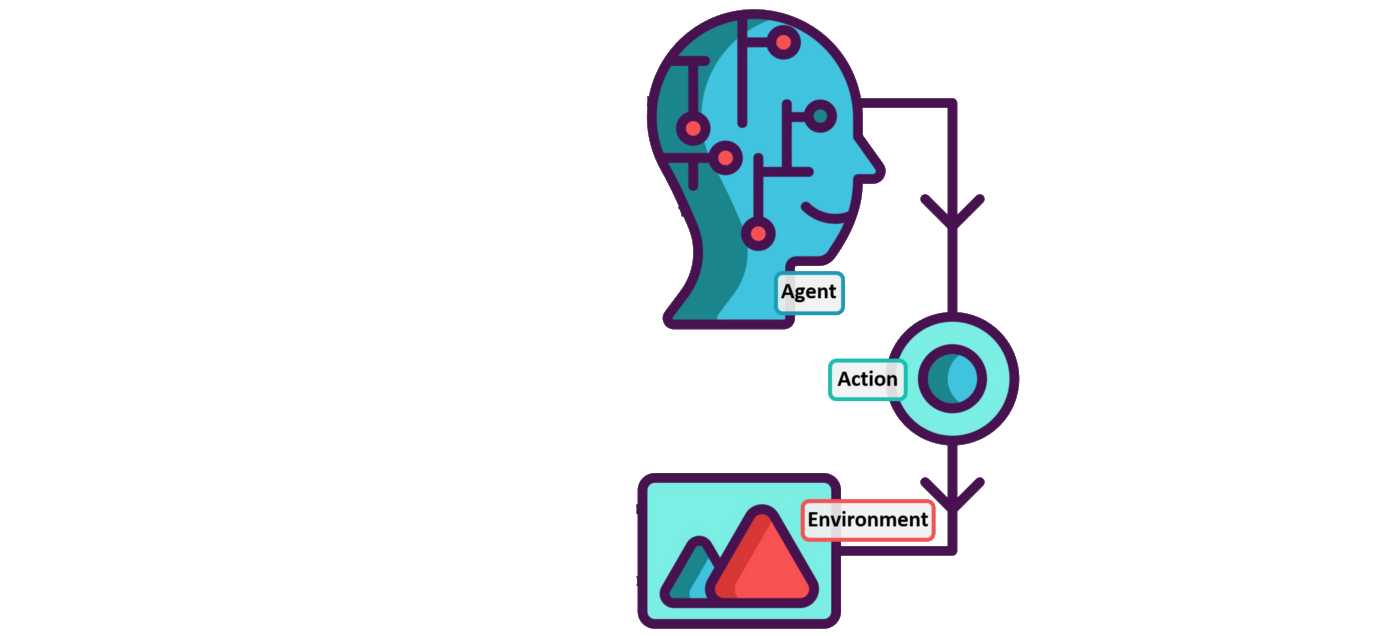
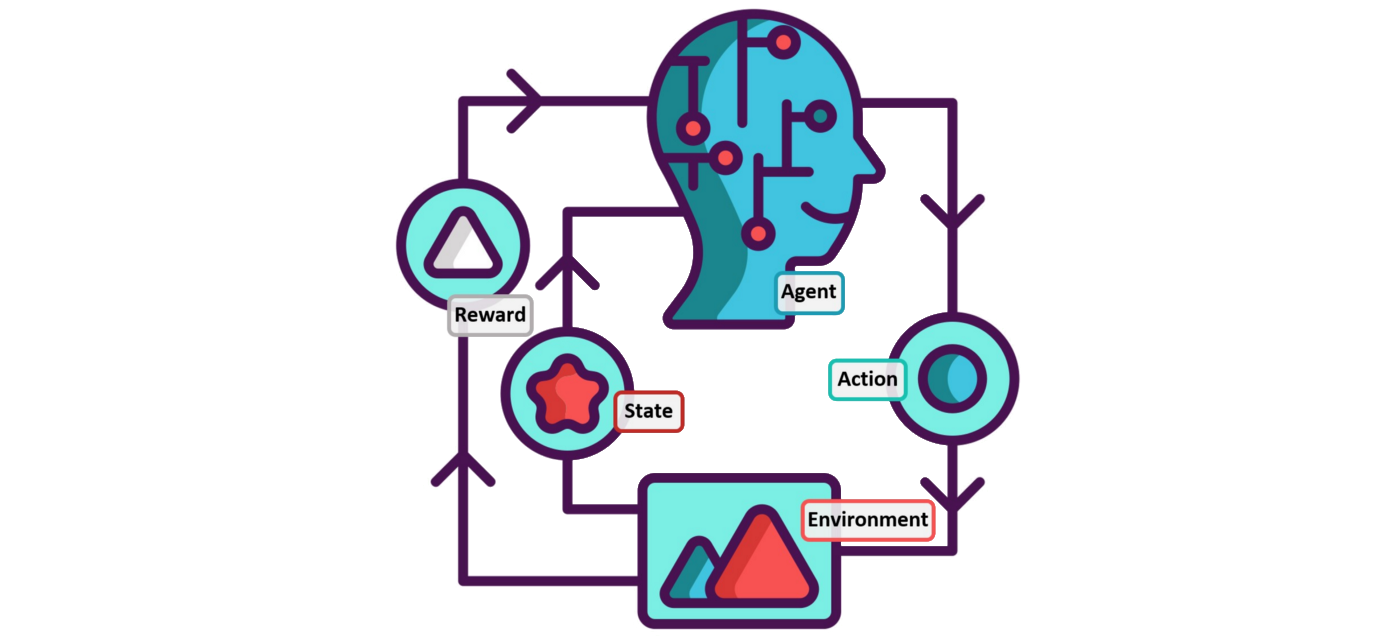
Simple, but flexible and extremely powerful
DQN in Atari
Alpha Zero
Hike And Seek
From Single-Agent To Multi-Agent
Multiple agents learn together the best policy that maximises a long-term reward signal.
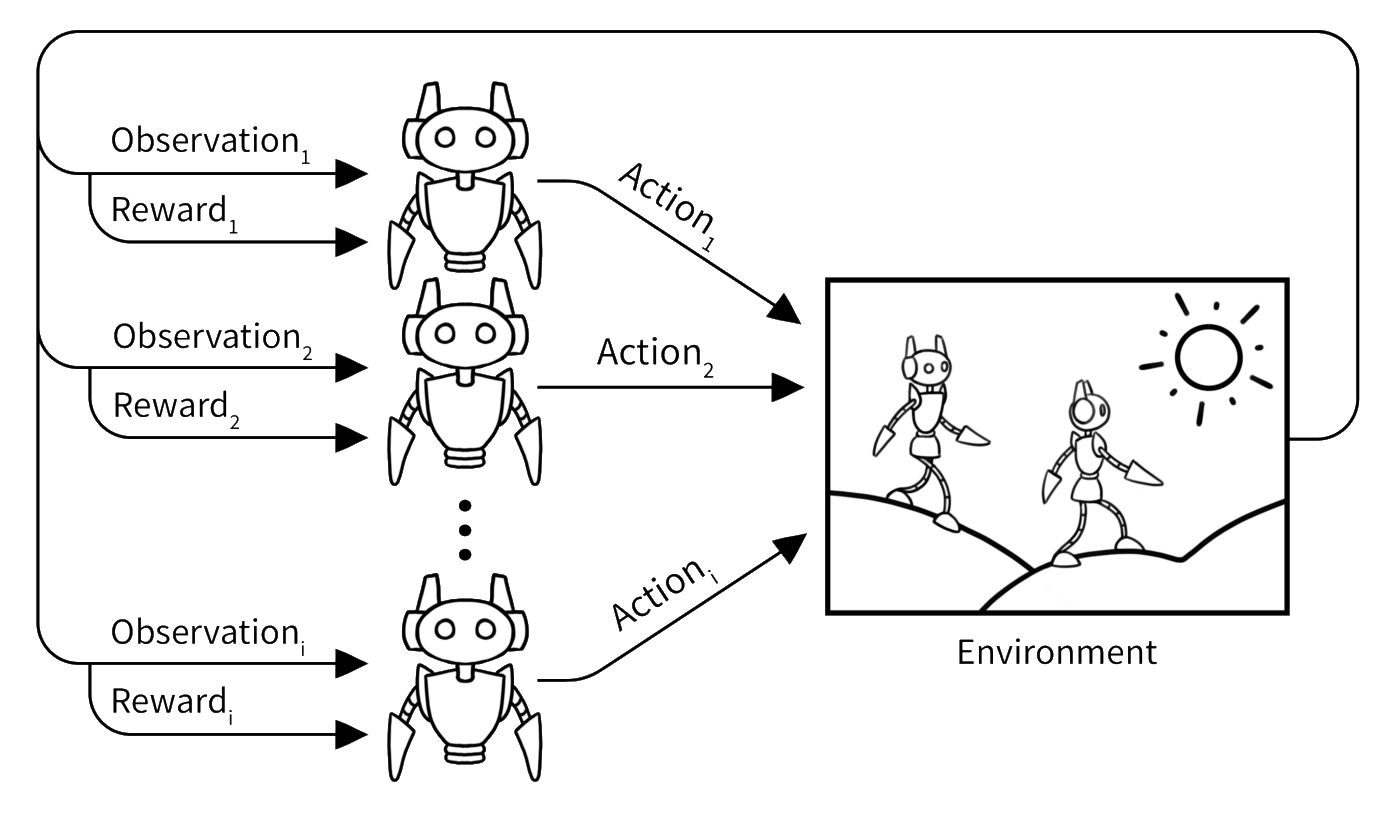
Multi-Agent Tasks
Cooperative
Cooperative

Competitive

Mixed
Cooperative Task
Homogenous
Homogenous
- each agent has the same capabilities
- goal: find the same policy that maximise the collective good
- typical choice for swarm-like systems
Heterogeneous
Learning Settings
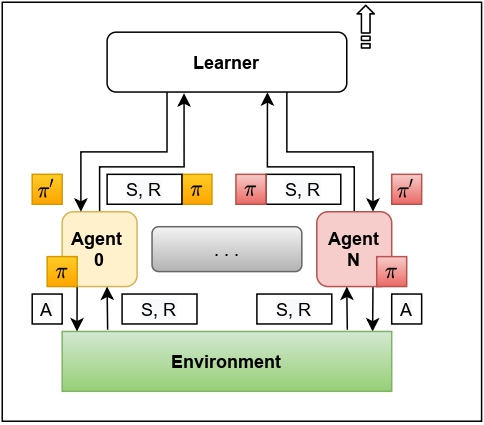
Centralised Training Centralised Execution
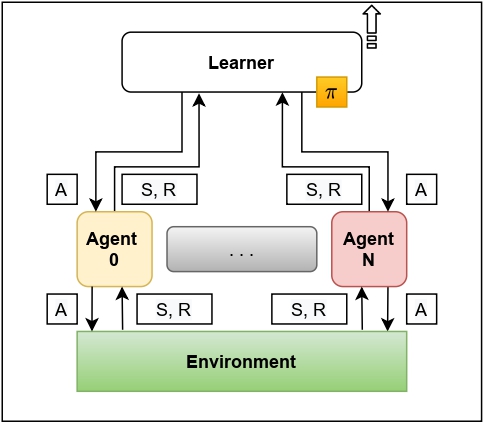
Decentralised Training Decentralised Execution
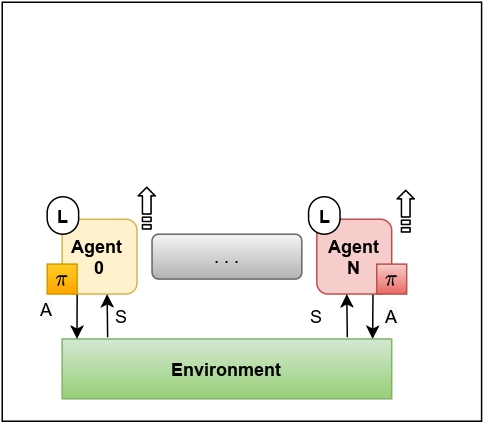
Centralised Training Decentralised Execution
Collective Program Sketching
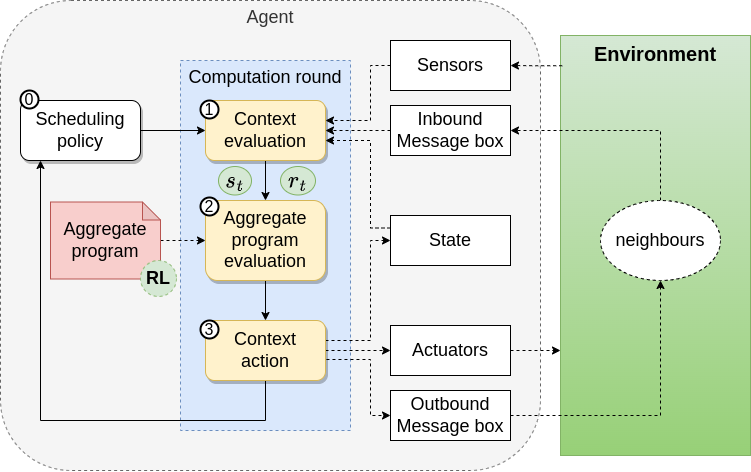
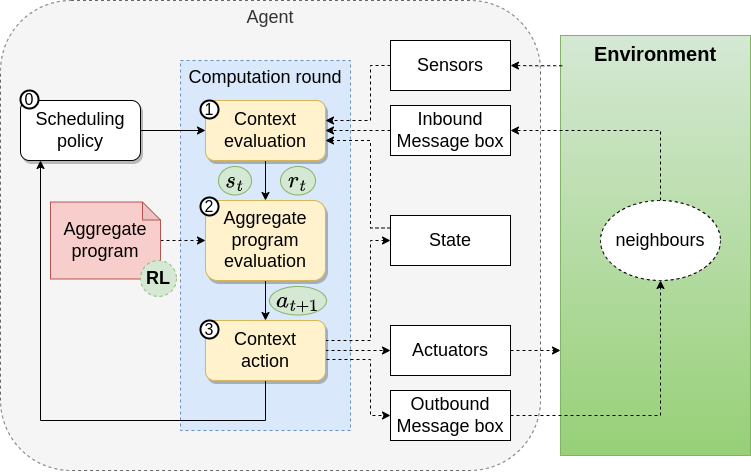
Aggregate Computing (Hysteretic) Q-Learning
Reference: G. Aguzzi et al, Towards Reinforcement Learning-based Aggregate Computing
High-Level idea
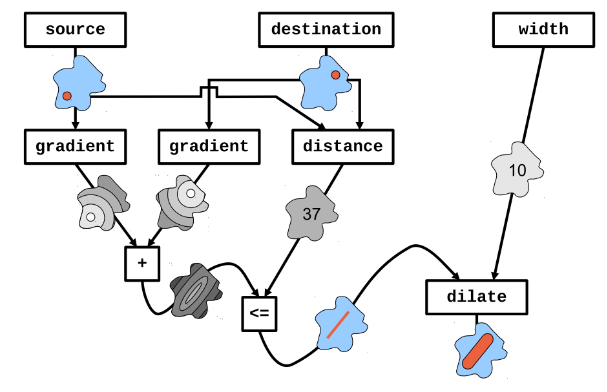
Aggregate Program
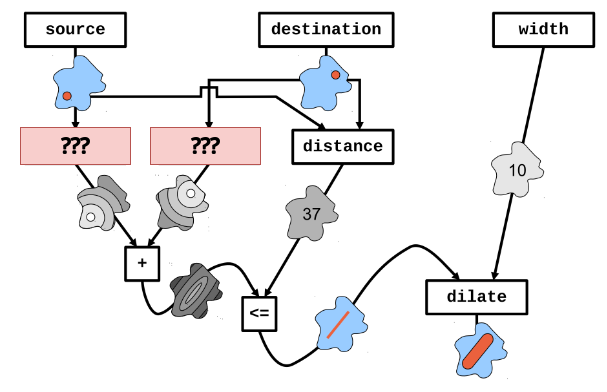
System-Dynamic Specific Part (Hole)
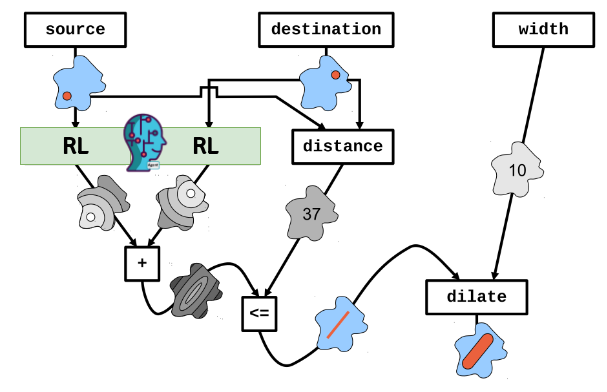
Fill the Hole through Experience
Execution Model
Revised
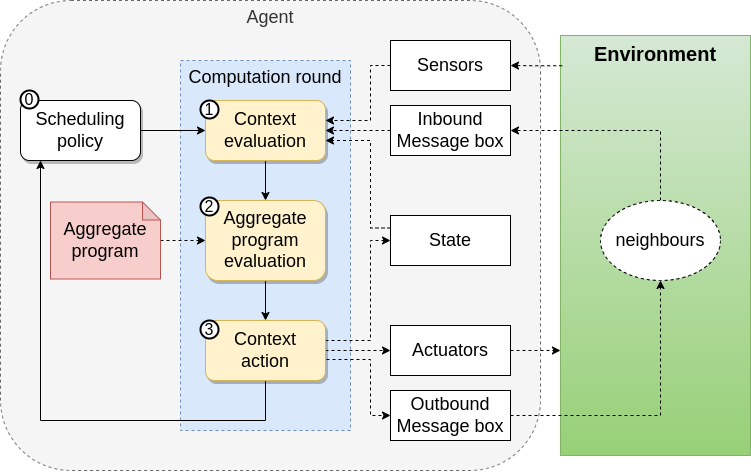
Learning Settings
Multi Agent Systems
Homogenous Behaviour
Centralised Traning Decentralised Execution

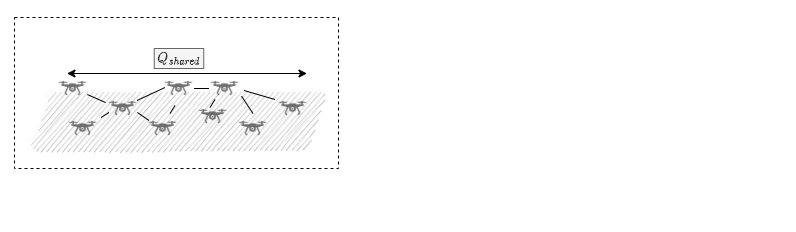
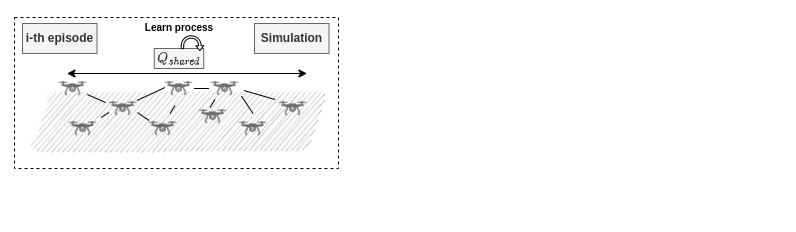
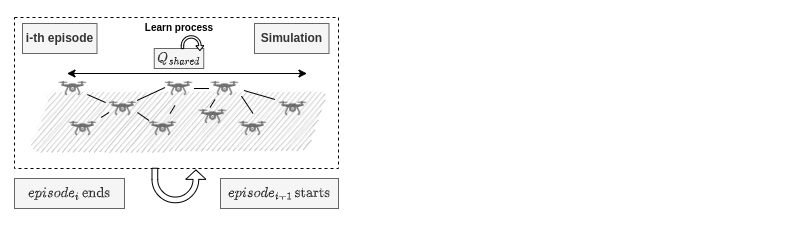
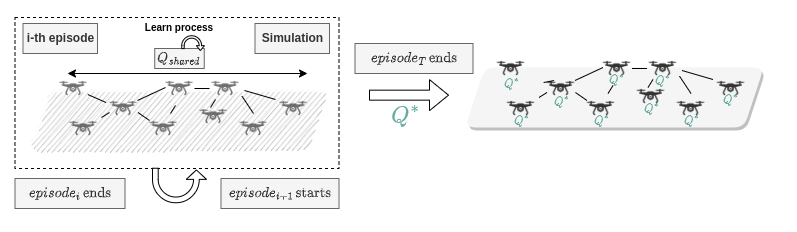
Case Study
Improve Gradient Cast
- Gradient Cast Main block for collective behavior
- Broadcast information
- Team formation
- High-Level pattern
- The behaviour could depend of the environment dynamics
- Several Issues: non-smooth output, slow-rising problem, problem with highly-dynamic nodes
- Typical approach: ad-hoc heuristic
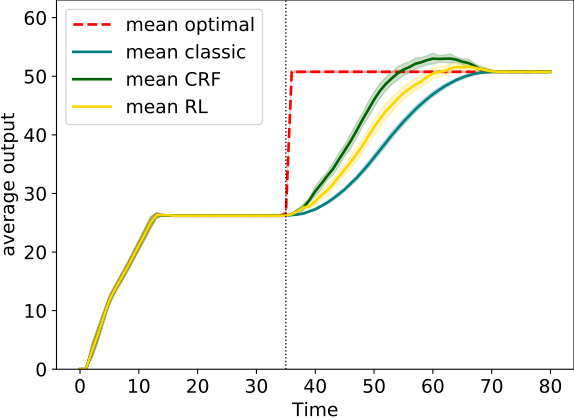
Preliminary Result
Handle slow rising problem
- State: a window of neighbours output
- Actions: decrease or increase output
- Reward: 0 if the output is the same of an oracle, -1 otherwise
Addressing Collective Computation Efficency
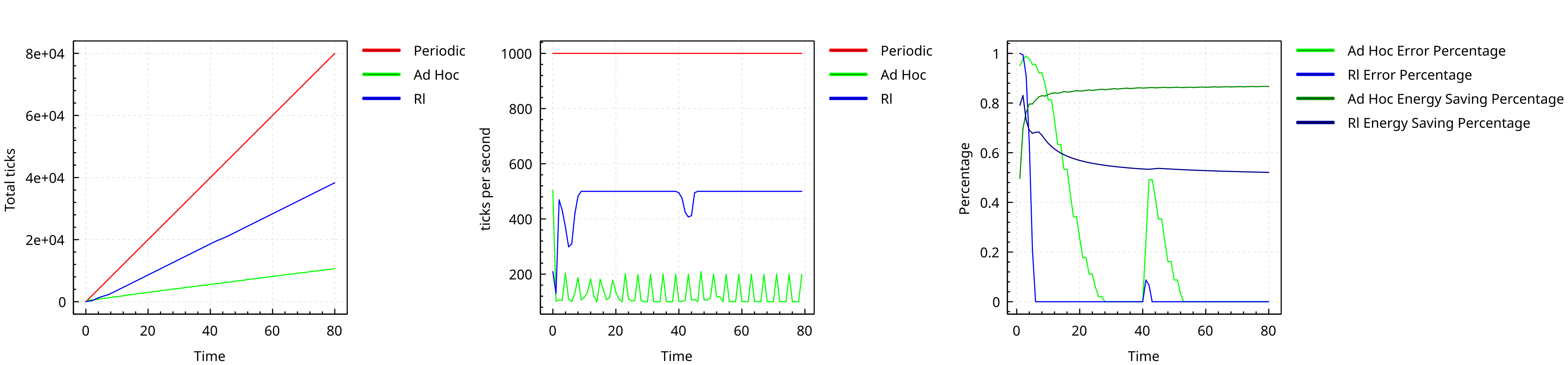
Distributed Schedulers through Q-Learning
Reference: G. Aguzzi et al, Addressing Collective Computations Efficiency through Reinforcement Learning
High-Level Idea
Adjust local scheduling following environment condition
- The Aggregate Computing model does not enforce a global-synchronization
- Current Implementation Periodic possibly async execution
- Frontier: Time-Fluid Field-Based Coordination through Programmable Distributed Schedulers
- Reinforcement Learning agent tunes the local node schedulers
Integration perspective
Learning goals
- Reducing the collective power consumption green computing
- Improve collective computation convergence time
- Multi-Objective problems
- Configurable balance between performance w.r.t. consumption
Case Study
Reduce the Power consumption of self-stabilizing Building blocks
- State: local output derivate
- Actions: next wake-up time
- Reward: near 0 if the output is stable, -1 in the other cases
Result overview
What we learn so far
Challenges
- Multi-agent credit assignment problem
- Multi-objective goals
- Hand-crafted state encoding are inadequate (variable neighborhood)
- Environment partial observability