Addressing Collective Computations Efficiency
Towards a Platform-level Reinforcement Learning Approach
Talk @ ACSOS 2022
🎤 Gianluca Aguzzi, Roberto Casadei, Mirko Viroli
Collective Adaptive Systems
Context
Many Networked Agents
Collective Behaviour
Challenges
- Distribution
- Uncertainties
- Global-to-local mapping
Motivating example
Distributed and resilient sensing
Use cases
- Monitoring wild fires in forests
- Crowd engineering
- Avalanche monitoring
- Agriculture monitoring system



How
Collective pattern
Building blocks for CAS applications
Gradient Cast
def diffuse(center, data, accumulator)

Broadcast information from sink nodes
Data collection
def collect(path, accumulator, data)

Collect data into sink nodes
Sparse Choice
def leaderElection(grain)

Distributed leader election
Self-organising & self-stabilising blocks
High-Level specification
General schema

val centers = leaderElection(grain)
val centers = leaderElection(grain)
val pathTo = diffuse(centers, 0, _ + connectionRange())
val centers = leaderElection(grain)
val pathTo = diffuse(centers, 0, _ + connectionRange())
val regionPerception = collect(pathTo, sense("perception"), accumulator)
val centers = leaderElection(grain)
val pathTo = diffuse(centers, 0, _ + connectionRange())
val regionPerception = collect(pathTo, sense("perception"), accumulator)
diffuse(centers, centerDecisionUsing(regionPerception), identity)
Execution Model
Behaviour
Loop of three phases:
Sense Compute Act
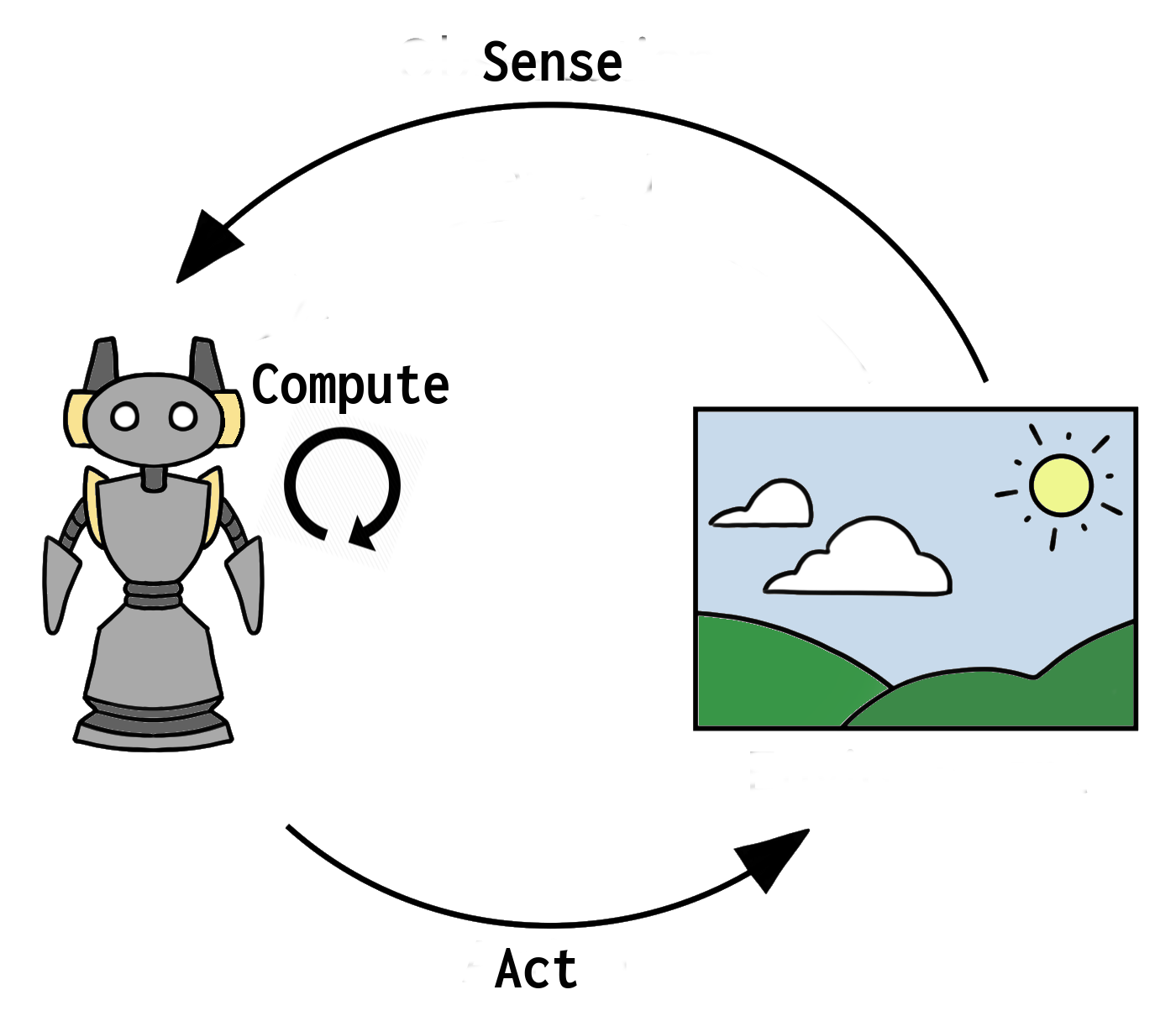
- Sense deals with neighborhood information retrieval & environment perceptions
- Compute performs the main logic of the application
- Act executes action following the result from Compute phase
Scheduling
- Message-based
- Execution triggered by messages received from the other
- Sensor-based
- Changes in the environment trigger execution
- Time-Based
- With a certain rate, nodes perform an execution step
- Event-based
On Collective Computing Efficiency
Goals
Approaches
On Collective Computing Efficiency
- Same Global specification (e.g., Distributed Sensing & Act)
Goals
Approaches
On Collective Computing Efficiency
- Same Global specification (e.g., Distributed Sensing & Act)
- Several Execution strategies
Goals
Approaches
On Collective Computing Efficiency
- Same Global specification (e.g., Distributed Sensing & Act)
- Several Execution strategies
- Collective Execution Strategies influence the Global result
Goals
Approaches
On Collective Computing Efficiency
- Same Global specification (e.g., Distributed Sensing & Act)
- Several Execution strategies
- Collective Execution Strategies influence the Global result
Goals
- Reduce power consumption Green computing
- Improve convergence time to the desired emergent
Multi-objective nature
Approaches
On Collective Computing Efficiency
- Same Global specification (e.g., Distributed Sensing & Act)
- Several Execution strategies
- Collective Execution Strategies influence the Global result
Goals
- Reduce power consumption Green computing
- Improve convergence time to the desired emergent
Multi-objective nature
Approaches
- Rule-Based Schedulers
- Reinforcement Learning-based Schedulers
On Collective Computing Efficiency
High Consumption, fast convergence
On Collective Computing Efficiency
Low Consumption, slow convergence
On Collective Computing Efficiency
Goal: adaptive solution
Contribution
Learning to reduce power consumption for self-stabilising building blocks (i.e., gradient-cast, data collection, sparse choice)
- Reference Learning Technique Value-Based Reinforcement Learning (e.g., Q-Learning)
- Reference Framework Aggregate Computing: A top-down global to local functional programming approach to express self-organising collective behaviours
- Good match for expressing our solution
- High potential-impact in the Aggregate Computing research
Contribution
Learning to reduce power consumption for self-stabilising building blocks (i.e., gradient-cast, data collection, sparse choice)
Benefits
- RL applied in the middleware – does not change the semantics of Aggregate Computing
- Separation between the Functionals aspect (i.e., the aggregate code) and Non-Functional aspects (i.e., the energy consumption)
Idea
- Time-based schedulers
- Learning how/when to reduce the round frequency …
- … Maintaining a good reactivity with respect to environmental changes
Learning Settings
Multi (Many) Agent System
- CASs foster systems with hundreds of computational entities
Homogenous Behaviour
- Complexity emerges from interactions
- Typical choice in swarm-like system
Centralised Training Decentralised Execution
- Global information during learning using the Q update
- distributed control at runtime state built from only local data
- learning eased by the global view

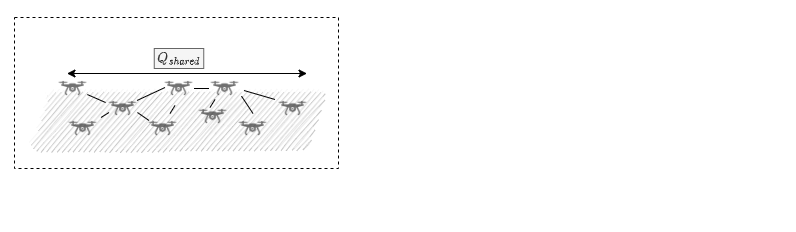
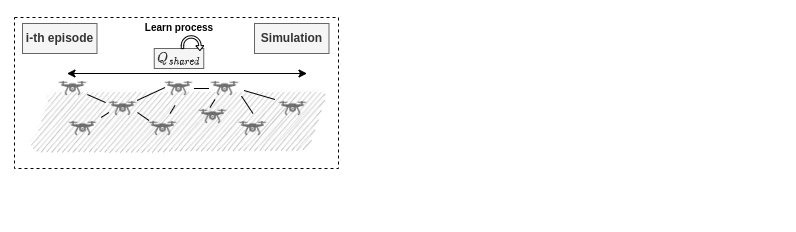
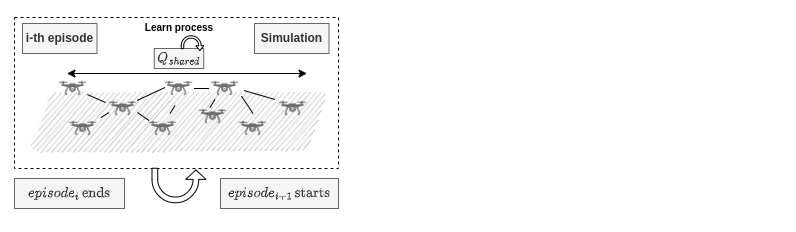
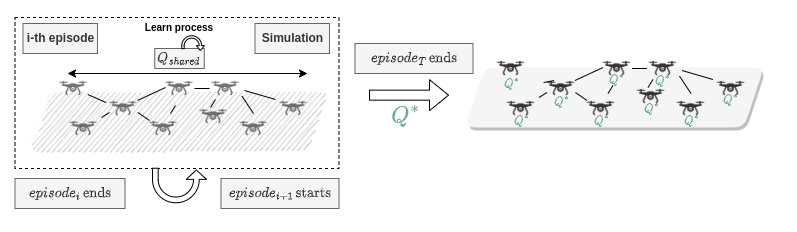
Learning Settings
For each time step, each agent record a $s_t, a_t, r_t$ trajectory, as:
- State: local output derivate
- Actions: next wake-up time
- Reward: near 0 if the output is stable, -1 in the other cases
Learning Settings
For each time step, each agent record a $s_t, a_t, r_t$ trajectory, as:
- State: local output derivate
- Window of size $w$ of local changes
- Each element could be
Rising,Stable,Decreasing
- Actions: next wake-up time
- Reward: near 0 if the output is stable, -1 in the other cases
Learning Settings
For each time step, each agent record a $s_t, a_t, r_t$ trajectory, as:
- State: local output derivate
- Actions: next wake-up time
- Fixed set:
[100ms, 200ms, 500ms, 1s]
- Fixed set:
- Reward: weight the next-wake time and the consumption
Learning Settings
For each time step, each agent record a $s_t, a_t, r_t$ trajectory, as:
- State: local output derivate
- Actions: next wake-up time
- Reward: near 0 if the output is stable, -1 in the other cases
- Multi-objective:
- non-stable condition: negative reward (-1)
- stable condition: weight the reward w.r.t. next wake up time – 0 if it is near to 1s
- $\theta$ weights the contribution of non-stability w.r.t. consumption
- Multi-objective:
Simulation Configuration
Goal
- Learn to reduce power consumption
- Blocks: Gradient-cast and Data collection
- Maintain a good convergence time
- Dual: with the same power, learn to converge more quickly
- Verify if the policy generalizes (i.e., work in other deployments)
Training
Evaluation
Simulation Configuration
Goal
Training
- 100 nodes in place in a semi-random grid
- each simulation has a random seed
- performance verified in different conditions
Evaluation
Simulation Configuration
Goal
Training
- 100 nodes in place in a semi-random grid
- each simulation has a random seed
- performance verified in different conditions
- multiple seek nodes
- multiple environmental changes
Evaluation
Simulation Configuration
Goal
Training
Evaluation
Simulation Configuration
Goal
Training
Evaluation
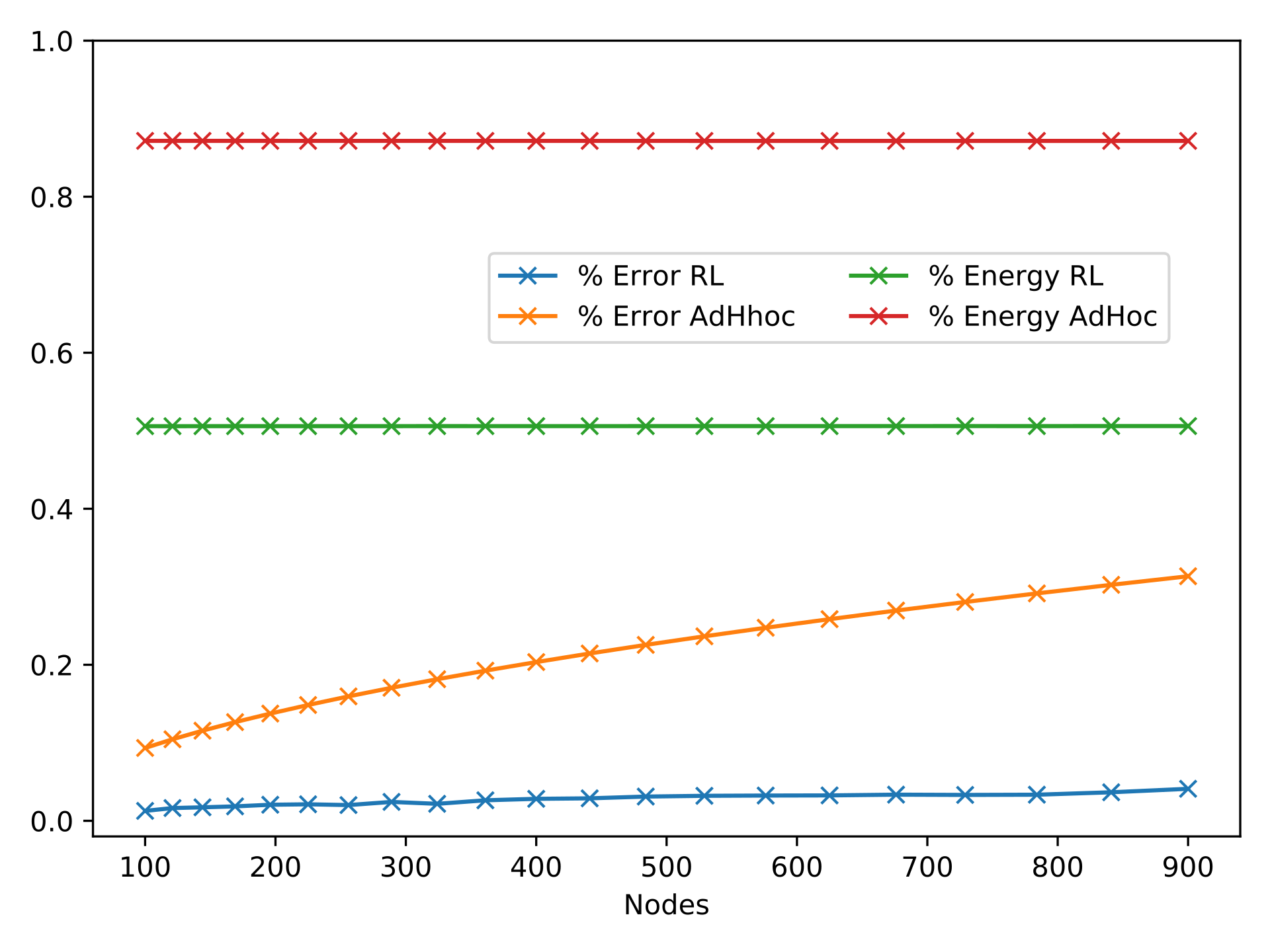
- Control the performance by varying the nodes in the system
- Compare with a hand-mand policy as a reference
Result Overview
Repository @ https://github.com/cric96/experiment-2022-acsos-round-rl
Training Process
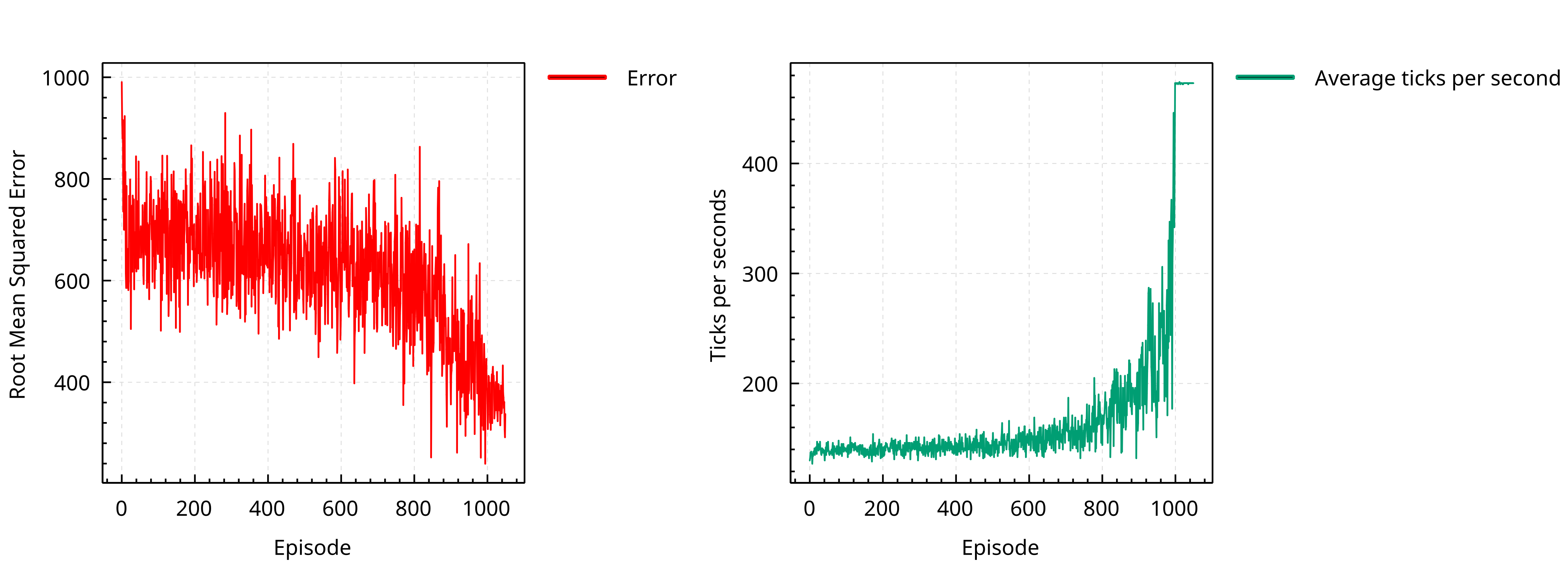
Policy Learn



Result Overview
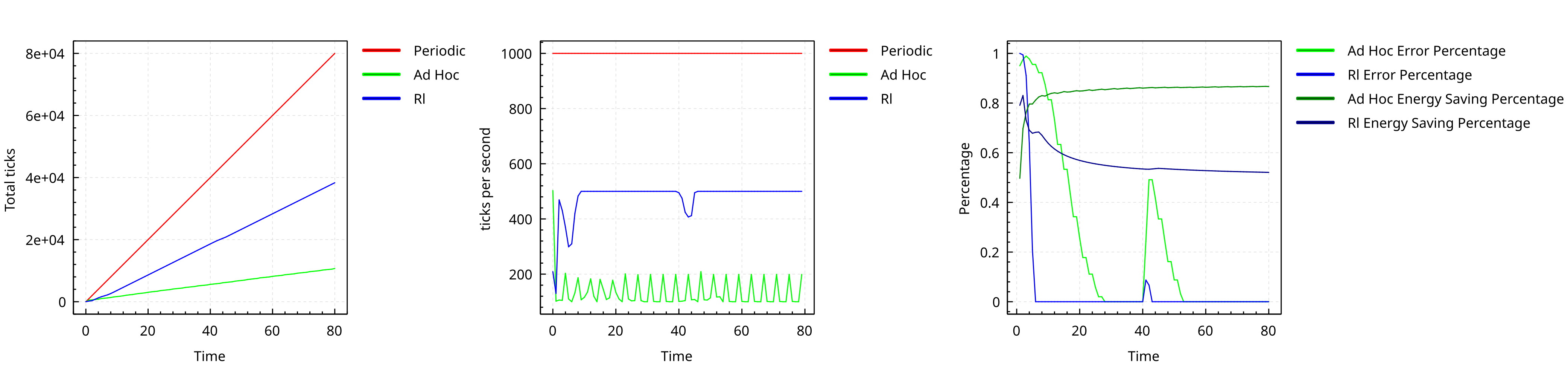
Performance with different seed
Performance varying the nodes
Conclusion
- The system eventually learns a policy that reduces the collective power consumption
- The same policy work for different deployments
Future Work
- Using scheduling policy as action
- Deep Learning approaches to encode local node features
- Using Multi-Objective Reinforcement Learning to better represent the problem space.
- Extends Learning to a fully online & distributed version